城市计算是一个交叉学科,是计算机科学以城市为背景,跟城市规划、交通、能源、环境、社会学和经济等学科融合的新兴领域。更具体的说,城市计算是一个通过不断获取、整合和分析城市中多种异构大数据来解决城市所面临的挑战(如环境恶化、交通拥堵、能耗增加、规划落后等)的过程。城市计算将无处不在的感知技术、高效的数据管理和分析算法,以及新颖的可视化技术相结合,致力于提高人们的生活品质、保护环境和促进城市运转效率。城市计算帮助我们理解各种城市现象的本质,甚至预测城市的未来[1][2][3]。 (English Homepage)
[1] Yu Zheng, Licia Capra, Ouri Wolfson, Hai Yang. Urban Computing: concepts, methodologies, and applications. ACM Transaction on Intelligent Systems and Technology. 5(3), 2014
[2] 郑宇. 城市计算概述,武汉大学学报. 2015年1月,40卷第一期
[3] 郑宇. 城市计算:用大数据和AI驱动智能城市, 中国计算机学会通讯. 2018年1月, 14卷第一期
[4] 演讲视频
- 2017年8月份:特邀报告(at KDD 2018)Urban Computing: Enabling Intelligent Cities with AI and Big Data (50 minutes), 2017.8, video.
- 2017年4月:CCF ADL 1小时报告 [视频讲解:深度学习在深空数据上的探索](用CCF会员号登陆后免费观看)
- 2017年3月清华演讲:城市计算:用大数据和AI驱动智能城市(视频和ppt)
- 2015年香港浸会大学:1小时视频(video)介绍城市计算的数据融合问题 。
[4] 轨迹数据挖掘综述: Yu Zheng. Trajectory Data Mining: An Overview. ACM Transaction on Intelligent Systems and Technology. 2015, vol. 6, issue 3. ) (A Tutorial)
[5] 跨域数据融合综述:Yu Zheng. Methodologies for Cross-Domain Data Fusion: An Overview. IEEE Transactions on Big Data, vol. 1, no. 1. 2015. (A Tutorial)
“城市计算”也是 郑宇博士 主持的一个研究项目。该项目从2008年初开始,通过分析和融合城市中的各种大数据,郑宇博士的团队实现了一系列关于智能交通、城市规划、环境和能源的实际案例。相关技术不仅被应用于微软的产品,并且还在多个城市服务于中国政府。
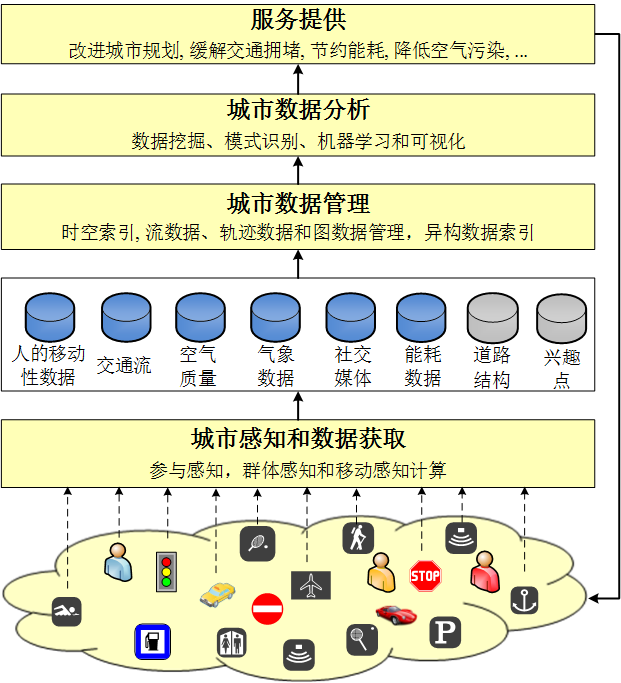
城市计算的框架
下图给出了城市计算的基本框架,包括城市感知及数据捕获、数据管理、城市数据分析、服务提供四个环节。与自然语言分析和图像处理等“单数据单任务”系统相比,城市计算是一个“多数据多任务”的系统。城市计算中的任务涵盖改进城市规划、缓解交通拥堵、保护自然环境、减少能源消耗等等。而在一个任务中又需要同时用到多种数据。比如,在城市规划的设计过程中,我们需要同时参考道路结构、兴趣点分布、交通流等多种数据源。
新闻专访和媒体报道
- SCDA智慧城市发展联盟:国家发改委城市和小城镇改革发展中心与京东集团达成战略合作,助力新型智慧城市建设. 2018-07-03
- 泰伯网:高端访谈:搭建城市计算生态,终结信息孤岛和重复建设. 2018-06-28
- 泰伯网:京东首席科学家、“城市计算”提出者郑宇:用大数据和AI打造新型智慧城市,与空间信息企业合作共赢. 2018.6.20
- 新京报:福州打造“三坊七巷”信用街区. 2018.6.11
- TechSir:数博会上”最”数字:京东金融AI指导火力发电 一年为国家节约一百亿. 2018.5.27
- 机器之心:京东金融城市计算论文入选IJCAI 2018,郑宇解读地理传感器时间序列预测问题. 2018.5.25
- 雷锋网:助力智慧城市建设,京东金融副总裁郑宇详解城市计算 | 世界智能大会. 2018.5.20
- 人民网:京东金融首席数据科学家郑宇:用大数据+AI打造新型智慧城市. 2018.5.18
- 坐标网:智能选址、AI火力发电等 京东金融郑宇用七个案例描绘智慧城市未来. 2017.5.17
- 网易新闻:郑宇博士入选2017中国AI英雄风云榜TOP10. 2017.12.4
- 微软AI头条号:大数据、人工智能、云计算和数据挖掘的区别和联系. 2017.10.10
- 上海第一财经:郑宇:城市计算让生活更智能,2017.9.4
- 交通运输部:城市交通的大数据解题思路,2017.6.23
- 雷锋网:为什么柯洁又输了,专业棋手反而觉得更加有希望了。2017.5.25
- 澎湃网:AlphaGo并没有攻克围棋难题,未来人类仍有希望。2017.5.23 (中国计算机学会公众号)
- 搜狐科技:人工智能如何管好大数据时代下的大城市,2017.5.1
- 大数据文摘:专访微软郑宇博士:这个时代不缺数据,缺的是不够开放的思维,2017.4.19
- 澎湃网:人流量千变万化难以预测,但微软通过大数据和人工智能做到了,2017.2.13
- 机器之心:专访 | 微软亚洲研究院郑宇:用人工智能进行城市人流预测, 2017.2.10
- 澎湃网:用大数据预测雾霾,微软是如何做到的?2017.1.2
- 郑宇博士当选为美国计算机学会杰出科学家(网易新闻)(搜狐新闻)。 2016.12.4
- China Daily: Microsoft, IBM eye Technology to forecast air pollution in China. 2016.1.19
- 中国科技报:环境从治理走向智理, 2016.1.11
- 中国环境报:预测雾霾,大数据能帮什么忙?,2015.12.14
- 新华网: 微软郑宇:大数据解决城市中的大挑战。2015.1.13
- 美国《财富》:评选郑宇为中国40位40岁以下的商界精英。2014.9.20
- 和讯网:微软郑宇:可利用大数据的分析解决城市问题。2014.4.19
- MIT科技评论:大数据如何解决北京的问题。2014.8.31
- 美国《时代》周刊:世界现代创新者代表之一:郑宇。2013.11
- 凤凰网(专访). 微软郑宇:大数据可预测空气污染 人人都是移动传感器. 2013.11.29
- 福布斯:郑宇:大数据如何改善城市交通。2013.8.23
- MIT科技评论:郑宇入选2013全球35位35岁以下杰出创新者(TR35).2013.8
典型案例
AI+智慧环保
大数据与城市环境
[1] 利用大数据和AI来应对城市空气污染
Public Website: http://urbanair.msra.cn/
项目简介:空气质量信息对控制污染和保护人们身体健康有着重要的意义。很多城市都开始建地面空气监测站来实时感知地面的空气质量。
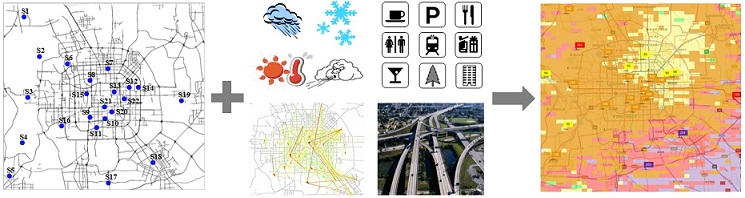
1)实时细粒度空气质量分析: 由于监测站的建设和维护成本高昂,一个城市通常只有有限个站点,并不能完全覆盖整个城市的范围。然而,受地表植被、交通流量、楼房密度和气象条件等各种复杂因素的影响,城市中不同地域的空气质量差异显著。因此,有限站点的读数并不能反映整个城市的空气污染情况,比如,当前位置恰好没有站点,我们就不知道他的空气污染状况。为解决这个问题,我们利用已有空气质量监测站点读数,结合气象、交通流、路网和兴趣点等多种数据源来实时分析细粒度的空气质量。该细粒度信息可指导人们出行,并为进一步研究空气污染根源提供基础。
论文:
[1] Yu Zheng, Furui Liu, Hsun-Ping Hsie. U-Air: When Urban Air Quality Inference Meets Big Data. 19th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2013).
[2] Yu Zheng, Xuxu Chen, Qiwei Jin, Yubiao Chen, Xiangyun Qu, Xin Liu, Eric Chang, Wei-Ying Ma, Yong Rui, Weiwei Sun. A Cloud-Based Knowledge Discovery System for Monitoring Fine-Grained Air Quality. MSR-TR-2014-40.
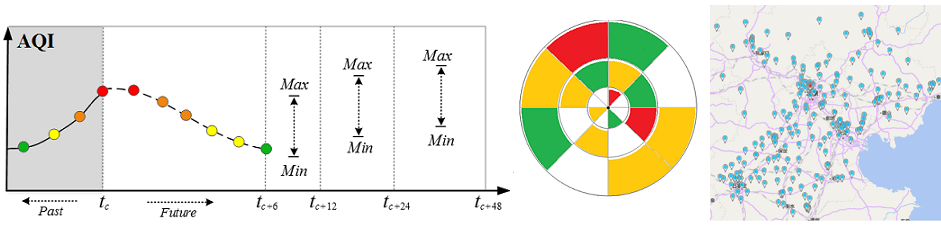
2)空气质量预测:城市各个地区未来空气质量如何也将影响政府的决策和人们的出行。该项目的第二个目标便是预测各个空气质量监测站点的未来48小时空气质量。该预报可以每小时更新,并可细化到站点级别的预测。其中前六小时可以做逐小时预报,7-12,12-24,25-48小时做一个最大-最小范围预报。
论文:
[1] Yu Zheng, Xiuwen Yi, Ming Li, Ruiyuan Li, Zhangqing Shan, Eric Chang, Tianrui Li. Forecasting Fine-Grained Air Quality Based on Big Data. In the Proceeding of the 21th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2015).
3)新站点选址:如果我们有一笔新的经费可以再建设几个空气质量监测站点,把这些站点建在哪里可以使得对整个城市空气质量监控的效果最好呢?该研究利用大数据分析的方法,为新建站点选择最佳的位置。
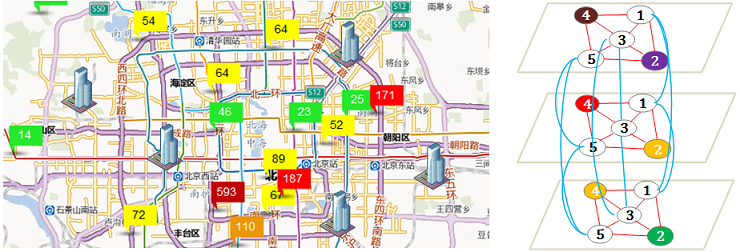
论文:
[1] Hsun-Ping Hsieh*, Shou-De Lin, Yu Zheng. Inferring Air Quality for Station Location Recommendation Based on Big Data. In the Proceeding of the 21th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2015).
4) 因果分析:利用机器学习方法和大数据来分析各地空气污染物在时空上的因果关系,找到空气污染的根源。
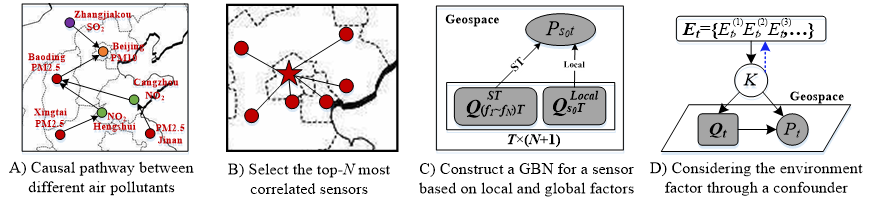
论文:
[1] Julie Yixuan Zhu, Chao Zhang, Huichu Zhang, Shi Zhi, Victor O.K. Li, Jiawei Han, and Yu Zheng, pg-Causality: Identifying Spatiotemporal Causal Pathways for Air Pollutants with Urban Big Data. IEEE Transactions on Big Data. DOI: 10.1109/TBDATA.2017.2723899
媒体报道:
- Analyzing newly available data about the intricacies of urban life could make cities better.” MIT Technology Review. 2013.8.21
- 凤凰网(专访). 微软郑宇:大数据可预测空气污染 人人都是移动传感器. 2013.11.29
- 新华网: 微软郑宇:大数据解决城市中的大挑战。2015.1.13
- 香港明报:微軟大數據分析 實時監測港空氣 2015.6.10
- ComputerWorld: Microsoft predicts China’s air pollution with data analysis, 2015.6.11
- GeekWire Reporter: What Microsoft Research is doing to help Beijing air pollution. 2015.11.30
- 中国环境报:预测雾霾,大数据能帮什么忙?,2015.12.14
- NBC News: Microsoft, IBM Eye Big Business Opportunity in China’s Air Pollution. 2015.12.28
- 路透社: Tech giants spot opportunity in forecasting China’s smog, 2015.12.28
- 澎湃:用大数据预测雾霾,微软是如何做到的?2017.1.2
下载:
- 实验数据:北京和上海的空气质量
- 手机应用程序下载:各种版本小鱼天气,英文WinPhone应用: ”Urban Air“;
更多信息请参看,城市空气项目主页。
—————————————————————–
[2] 基于大数据和AI的城市噪音诊断
项目简介:城市的发展带来了很多噪音源,如汽车鸣笛、酒吧和建筑施工等。这些噪音不仅会影响人的睡眠质量、降低工作效率,还会对人体的精神和健康产生危害。应对城市噪音污染首先要了解整个城市的噪音状况和噪音构成。但对整个城市的噪音建模却非常困难。首先,噪音随时间变化很快,随空间变化剧烈。要监控细粒度的城市噪音需要安装数百万声学传感器,这种做法很不现实。此外,噪音污染的衡量不仅仅取决于噪音的强弱(分贝数),还取决于人们对噪音的容忍度,而后者会随着时间的变化而变化。再者,噪音通常是多种声音源的混合体。单纯的传感器数据只能反应声音的强弱,却不能解析噪音的构成。本项目利用纽约市民对噪音的抱怨数据(311数据),将人作为一个智能传感器,以群体感知的方式,并结合路网数据、兴趣点数据和社交媒体中的签到数据来协同分析各个区域在不同时间段和噪音类别上的污染指数。有了这样细粒度的噪音指数,我们可以理解城市中各个区域的噪音状况,并诊断噪音构成。
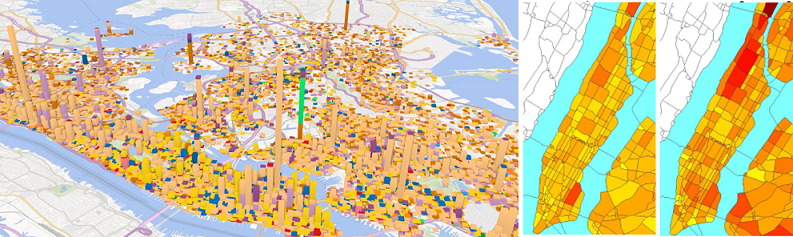
论文:
[1] Yu Zheng, Tong Liu, Yilun Wang, Yanchi Liu, Yanmin Zhu, Eric Chang. Diagnosing New York City’s Noises with Ubiquitous Data. In Proceedings of the 16th ACM International Joint Conference on Pervasive and Ubiquitous Computing (UbiComp 2014).
[2] Tong Liu, Yu Zheng, Lubin Liu, Yanchi Liu, Yanmin Zhu. Methods for Sensing Urban Noises. MSR-TR-2014-66, May 2014.
[3] Yilun Wang, Yu Zheng, Tong Liu. A Noise Map of New York City. In Proc. of Ubicomp 2014, Demo.
下载:
————————————————————–
[3] 基于人工智能的城市管网水质预测
该项目利用城市管网中有限的水质传感器数据和流量数据,结合气象、地理信息和管网结构等多源数据来预测各个测点未来12小时内的水质变化。该预测信息可以帮助自来水厂及时、准确调节出厂水质中的各项指标,保证人们的用水安全。当预测与实际值差别很大时,可能预示着管网出现了某种问题。
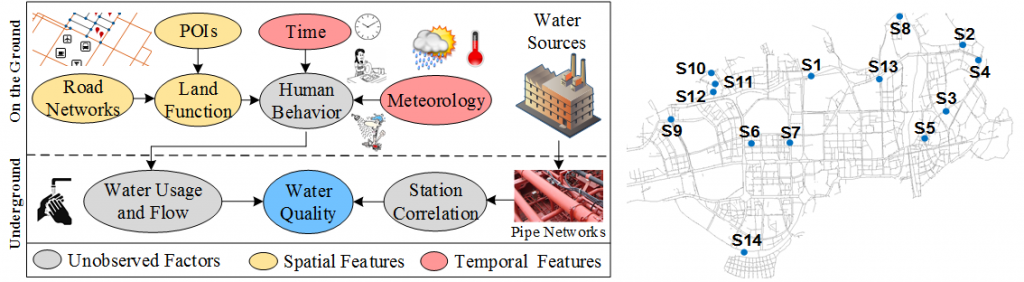
论文:
[1] Ye Liu, Yu Zheng, Yuxuan Liang, Shuming Liu, David S. Rosenblum, Urban Water Quality Prediction based on Multi-task Multi-view Learning , in Proceedings of the 25th International Joint Conference on Artificial Intelligence (IJCAI 2016)
AI+智能交通
[1] 实时大规模动态拼车服务
项目简介:打车难是很多大城市都面临的一个问题。本项目通过出租车实时动态拼车的方案来解决这一难题。用户通过手机提交打车请求,表明上、下车地点、乘客人数和期望到达目的地间。后台系统实时维护着所有出租车的状态,在接收到一个用户请求后,搜索出满足新用户条件和车上已有乘客条件的最优的车。这里的最优是指出租车去接一个新的用户所增加的里程最小。该研究成果可以为城市节约大量的燃油、减少污染物排放量,大大提高整个出租车系统的运送能力,缩短乘客的等待时间,降低乘客的打车费用并提高司机的收入。项目难点在于如何能高效的索引并计算出最优的车辆和拼车线路。
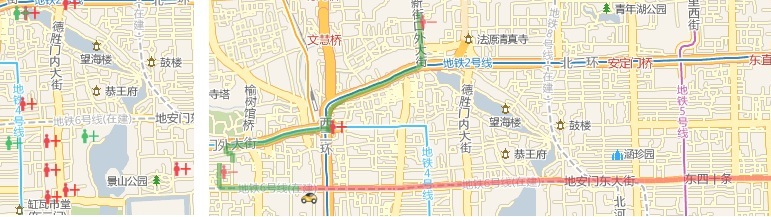
论文:
[1] Shuo Ma, Yu Zheng, Ouri Wolfson. T-Share: A Large-Scale Dynamic Taxi Ridesharing Service. IEEE International Conference on Data Engineering (ICDE 2013) Best Paper Runner-up Award.
[2] Shuo Ma*, Yu Zheng, Ouri Wolfson. Real-Time City-Scale Taxi Ridesharing. IEEE Transactions on Knowledge and Data Engineering (TKDE), vol. 27, No. 7, July 2015. [Codes] [Data]
—————————————————————————
[2] 基于AI的路线通行时间估计
项目简介: 根据一部分车的GPS轨迹数据,实时地估计全城任意路线的车辆通行时间。项目难点在于以下三点:1. 数据稀疏性。在过去的一段时间里,很多道路上并没有轨迹数据。2. 不同轨迹的组合问题。对于有数据的路段,有很多种子轨迹组合的方式来估计时间。寻找最优解很困难。3. 效率、准确性和可扩展性的权衡。城市范围很大,轨迹快速变化,子轨迹组合方式很多,但时间估计的实时性要求很强。
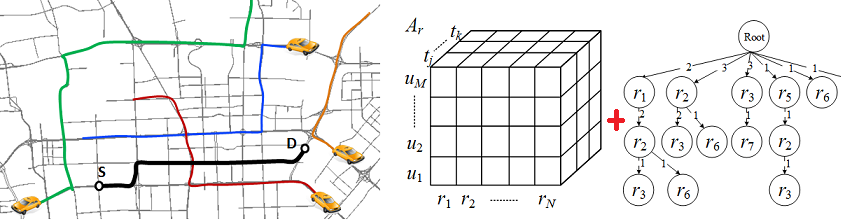
论文:
[1] Yilun Wang, Yu Zheng, Yexiang Xue. Travel Time Estimation of a Path using Sparse Trajectories. In Proceedings of the 20th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2014).
数据和代码下载:Data and codes
——————————————————————————
[3] 基于出租车GPS轨迹的最快行车路线设计
项目简介:装有GPS的出租车可以看作是移动传感器来帮助我们不断感知路面的交通流量,而且出租车司机是相对有经验的司机。所以,出租车的GPS轨迹既体现了交通流量的变化规律,也蕴含了人们选择道路的智能。本项目(T-Drive)利用北京3万多辆装有GPS传感器的出租车来感知交通流量,并为普通用户设计真正意义上的最快驾车线路。T-Drive的改进版进一步考虑了天气以及个人驾车习惯、技能和道路熟悉程度等因素,提出了个性化最快线路设计。这个系统不仅可以为每30分钟驾车路程节约5分钟时间,也可以通过让不同用户选择不同的道路来缓解可能出现的拥堵。

论文:
[1] Jing Yuan, Yu Zheng, et al. T-Drive: Driving Directions Based on Taxi Trajectories. In ACM SIGSPATIAL GIS 2010, The Best Paper Runner-Up Award.
[2] Jing Yuan, Yu Zheng, et al. Driving with Knowledge from the Physical World. 17th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2011).
[3] Jing Yuan, Yu Zheng, et al, T-Drive: Enhancing Driving Directions with Taxi Drivers’ Intelligence. Transactions on Knowledge and Data Engineering (TKDE).
媒体报道:
- Adding cabbie know-how to online maps, MIT Technology Review, 2010.11.6
- Follow that cab! Racing Google Maps on city streets, NewScientist, 2010.11.5
- “A driving route made just for you“, MIT Technology Review, 2011.8.30.
————————————————————————–
[4] 自行车租借系统使用需求预测
项目简介:自行车租借和共享系统在很多城市都得到了普及。由于人们在各个站点对自行车的需求不一致,导致某些站点出现无车可借,而另一些站点可能会出现大量车被换回而无法接纳。因此,提前预测各个自行车租赁点人们对车的需求量(如在未来一个小时各个站点的借出和还回的自行车数量),将有助于提前调度不同租赁站点之间的自行车,做到供求平衡。由于人们对自行车的需求受到很多复杂因素的影响,如天气、事件和站点间的相互影响,预测单个站点自行车的借出和还回数量非常困难。文章[1]采用了聚类和层次化预测的方法来克服这些难点。
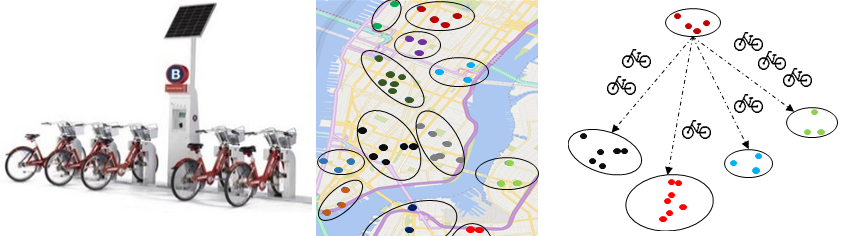
论文:
[1] Yexin Lee, Yu Zheng, Huichu Zhang, Lei Chen. Traffic Prediction in a Bike Sharing System, In Proceedings of the 23rd ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2015) (Data)(Codes)
AI+城市规划
大数据+AI革新城市规划
[1] 利用人的移动性和地理数据发掘城市的功能区域
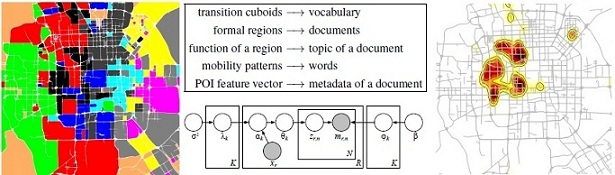
项目简介:城市的不断发展催生了不同的功能区域,如文教、商业和住宅区等。准确掌握这些区域的分布对制定合理的城市规划有着极其重要的意义。由于一个区域的功能并不是单一的,如在科学文教区里仍然有饭店和商业设施的存在,一个区域需要由一个功能的分布来表达(如70%的功能为商业,20%的功能为住宅,剩余的为教育)。另一方面,一个区域的主要功能是文教,但也不代表该区域的任何一个地点都服务于文教。因此,给定一种功能,我们希望知道它的核心区域所在。结合兴趣点数据和人们的移动模式,本项目分析了城市中不同的功能区域,以及每种功能的核心所在。
论文:
[1] Jing Yuan, Yu Zheng, Xing Xie. Discovering regions of different functions in a city using human mobility and POIs. 18th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2012).
[2] Nicholas Jing Yuan, Yu Zheng, Xing Xie, Yingzi Wang, Kai Zheng, Hui Xiong. Discovering Urban Functional Zones Using Latent Activity Trajectories, IEEE Transactions on Knowledge and Data Engineering (TKDE), 2016.
—————————————————————————
[2] 基于人的移动性数据来发现不合理道路规划
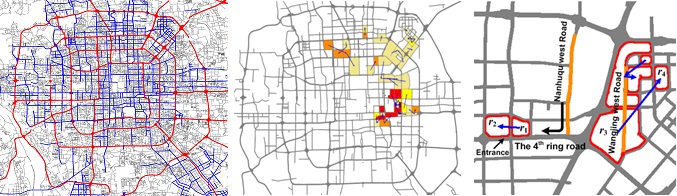
项目简介: 城市拥堵的凸显有一定程度是由于现有道路网的设计已经不能满足不断发展的城市交通流的需求。如图上图左1所示,利用高速和环路等主干道将城市分割成区域,然后分析大规模车流轨迹数据在不同区域之间行驶的一些特征,便可找到连通性较差的区域对,从而发掘现有城市道路网的不足之处。上图左2给出了基于北京市3万多辆出租车3个月轨迹数据的一个分析结果。这些结果可以作为制定下一版规划的参考建议。同时,通过对比连续两年的检测结果,我们可以验证一些已经设施的规划(如新建道路和地铁)是否真的有效。
论文:
[1] Yu Zheng, Yanchi Liu, Jing Yuan, Xing Xie, Urban Computing with Taxicabs, 13th ACM International Conference on Ubiquitous Computing (UbiComp 2011), Beijing, China, Sep. 2011. The best paper nominee award.
[2] 下载地图分割算法
媒体报道
- “Taxicab data helps ease traffic“. Future of Technology on NBCNEWS.com. 2011.9.29
- “GPS Data on Beijing Cabs Reveals the Cause of the Traffic Jams“. MIT Technology Review, 2011.9.27. Featured on the first page.
- “Urban computing based on taxicabs”. Reported by ACM TechNews. 2011.9.27
—————————————————————
[3] 基于出行数据的城市黑洞和火山发掘
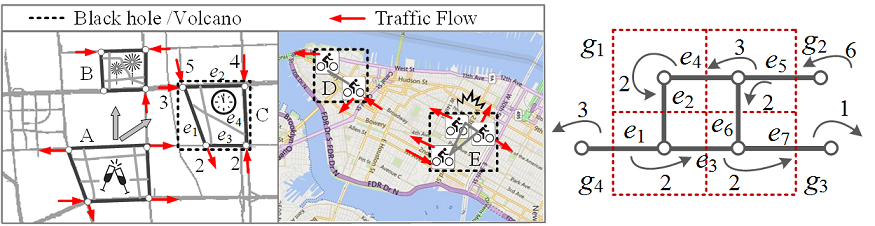
项目简介:城市黑洞是指在一段时间内一个区域里的进入人群数量远远大于流出人群数量。而城市火山则恰恰相反。实时地检测城市黑洞和火山可以及时的捕捉异常事件,帮助交通管理和提前预警,从而防止悲剧发生。长期的黑洞和火山的出现以及他们之间的转移概率可以帮助了解人们的出行模型,从而改进城市规划。
论文:
[1] Liang Hong, Yu Zheng, Duncan Yung, Jingbo Shang, Lei Zou. Detecting Urban Black Holes Based on Human Mobility Data. In Proceedings of the 23rd ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2015). (Codes) (Data)
[4] 基于共享单车轨迹数据的自行车道规划
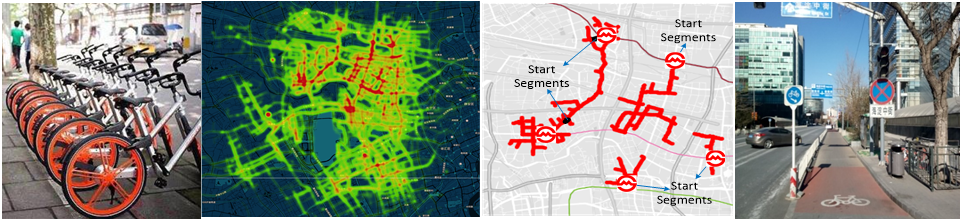
共享单车的出现解决了人们出行最后一公里的问题,并再一次激发了国人的骑行需求。但目前的自行车道规划已经跟不上人们的骑行需求,政府如何利用有限的资源来合理的修建自行车道变得迫在眉睫。该项目利用摩拜自行车轨迹数据,结合人工智能算法来合理规划自行车道,提高人们的骑行体验,保障出行安全,并为政府节约资源。
论文
[1] Jie Bao, Tianfu He, Sijie Ruan, Yanhua Li, Yu Zheng. Planning bike lanes based on Sharing-bike’s trajectories. in Proceedings of the 23th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2017).
媒体报道:
[1] 微软研究院AI头条号:大数据freestyle: 共享单车轨迹数据助力城市合理规划自行车道, 2017.8.22
AI+城市异常和安全
A. 基于大数据的人流预测
[1] 城市区域人流预测
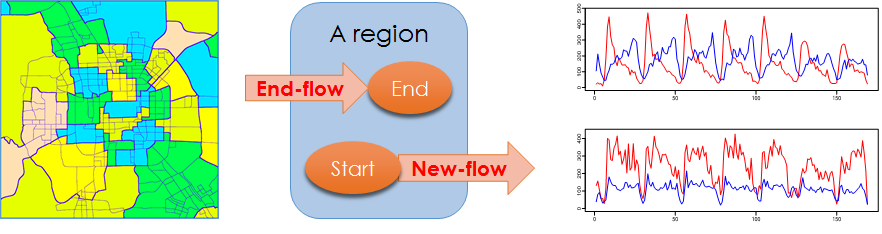
项目简介:将城市通过主干道分成具有语义信息的区域,通过融合交通、气象和事件等各种大数据,预测各个区域内未来几小时人流进入和流出的数量,以便提前启动预警机制,及早疏导人群和车流,保障区域内短时人口密度在安全范围内,从而防范重大交通事故和灾难性城市安全事件(如踩踏)的发生。
论文:
[1] Minh X. Hoang, Yu Zheng, Ambuj K. Singh. FCCF: Forecasting Citywide Crowd Flows Based on Big Data. in Proceedings of the 24th ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2016) (PPT)
下载数据和代码!
[2] 基于深度学习的城市网格人流预测
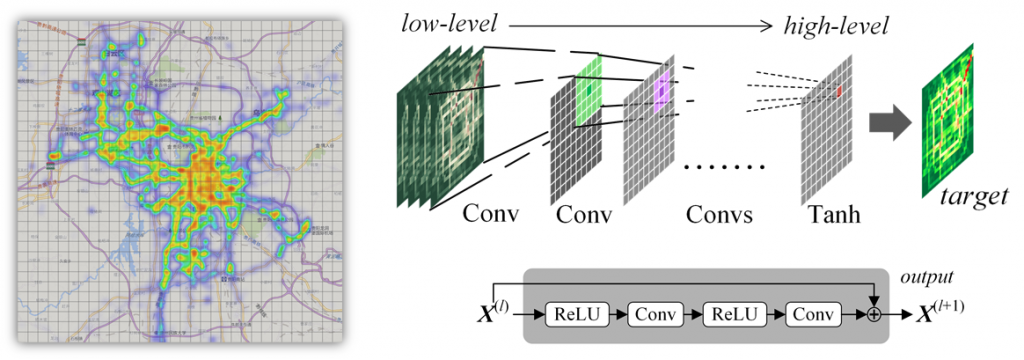
项目简介:将城市分割成均匀网格,基于交通、气象、时间和事件等多源信息,采用深度学习(Deep Learning)的方法,来综合预测未来每个网格的进入和流出人流数,以便提前启动预警机制,及早疏导人群和车流,保障区域内短时人口密度在安全范围内,从而防范重大交通事故和灾难性城市安全事件(如踩踏)的发生。在采用深度学习算法时,我们充分考虑的时空数据的属性,设计的更为合理的网络结构来模拟人流数据的周期性、趋势性和时空的邻近性等特征,取得了比简单CNN更好的效果。(演示系统)
论文:
[1] Junbo Zhang, Yu Zheng, Dekang Qi. Deep Spatio-Temporal Residual Networks for Citywide Crowd Flows Prediction, In Proceedings of the 31st AAAI Conference (AAAI 2017). (code)(data)(system)
[2] Junbo Zhang, Yu Zheng, Dekang Qi, Ruiyuan Li, Xiuwen Yi. DNN-Based Prediction Model for Spatial-Temporal Data. in Proceedings of the 24th ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2016) Demo Paper (arXiv version)
媒体报道:
[1] 机器之心:专访 | 微软亚洲研究院郑宇:用人工智能进行城市人流预测, 2017.2.10
[2] 澎湃网:人流量千变万化难以预测,但微软通过大数据和人工智能做到了,2017.2.13
[3] 2017年4月:CCF ADL 1小时报告 [视频讲解:深度学习在深空数据上的探索]
________________________________________
B. 大数据与城市异常
[1] 交通异常分析
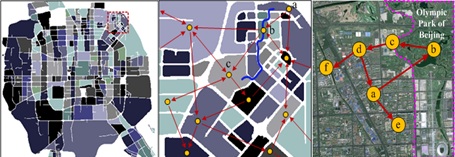
项目简介:城市中总是会有一些突发事件,比如自然灾害(地震和洪水等)、大型赛事和商业促销、交通事故和临时管制、以及一些群体性事件。如果能及时感知、甚至预警这些事情,将能极大的帮助城市管理,提高政府对突发事件的应对能力,保障城市安全、减少悲剧的发生。文献[1][2][3][4]通过分析北京3万多辆出租车的轨迹来发现城市中的异常事件。其主要思想是当异常事件发生时,附近的交通流将出现一定程度的紊乱。
论文:
[1] Wei Liu, Yu Zheng, Sanjay Chawla, Jing Yuan and Xing Xie. Discovering Spatio-Temporal Causal Interactions in Traffic Data Streams. In KDD 2011.
[2] Linsey Xiaolin Pang, Sanjay Chawla, Wei Liu, and Yu Zheng. On Mining Anomalous Patterns in Road Traffic Streams. In the 7th International Conference on Advanced Data Mining and Applications (ADMA 2011). The best paper award
——————————————————————————
[2] 解释和诊断交通异常
文献[3]试图用具体的交通线路来进一步解释异常出现的原因。有时候,两个区域之间出现了交通流异常,但问题本身可能并不在这两个区域,而在于远处的车流必须通过这两个区域前往另一个目的地。这些车流才是问题的根源。[4]根据司机们路线选择方式的改变来捕捉交通异常,并进一步从相关的微博中提取关键词来解释异常的原因,如婚博会、道路坍塌。

[3] Sanjay Chawla, Yu Zheng, and Jiafeng Hu. Inferring the root cause in road traffic anomalies, IEEE International Conference on Data Mining (ICDM 2012).
[4] Bei Pan, Yu Zheng, David Wilkie, and Cyrus Shahabi. Crowd Sensing of Traffic Anomalies based on Human Mobility and Social Media. ACM SIGSPATIAL GIS 2013
—————————————————————-
[3] 通过多源数据来检测整体城市异常
整体异常是指位置邻近的一些小区域的集合在一段时间里出现了跟平时很不一样的表征,这些表征从单一数据上可能无法反映,但集合多个数据源便能看出这些潜在的异常。
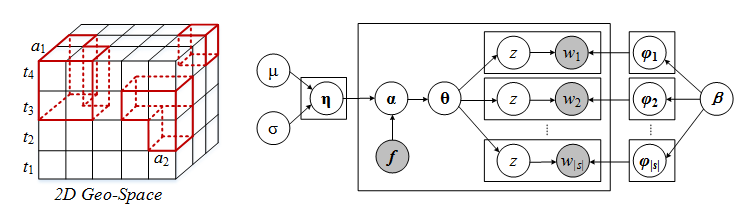
[1] Yu Zheng, Huichu Zhang, Yong Yu. Detecting Collective Anomalies from Multiple Spatio-Temporal Datasets across Different Domains. In Proceedings of the 23rd ACM International Conference on Advances in Geographical Information Systems (ACM SIGSPATIAL 2015). (Data) (Codes)
AI+城市金融、社交和娱乐
大数据与金融、社交和物流
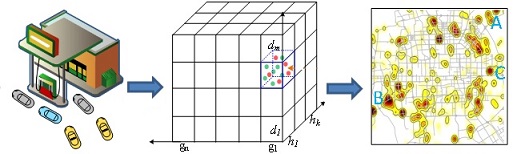
[1] 基于大数据的房屋价值排序和商业选址模型
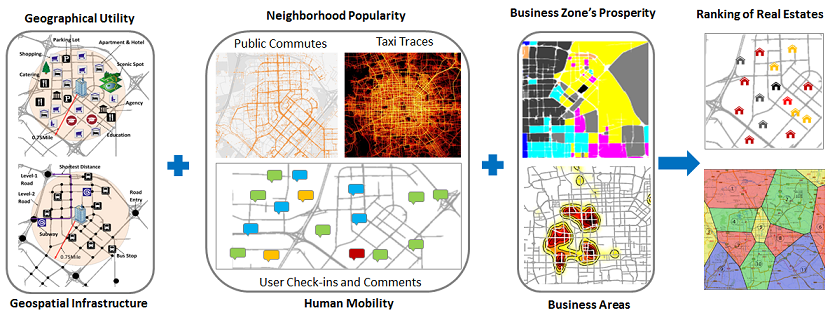
决定房屋价值的重要因素,第一是地段,第二是地段,第三还是地段。地段可以具体量化为周边的配套设施(道路结构、地铁、公交车站、商场和学校等)、人气(有多少人来,怎么来,如通过地铁、公交和出租车来的人数以及人们对这些地方的评价)和整个社区的品质。集合多源数据来做一个房屋价值的排序,可以帮助我们选择高价值的房子。这个模型也可以变成通用的商业选择模型,不仅仅局限于房地产行业的选址。请参看相关论文:
论文:
[1] Yanjie Fu, Hui Xiong, Yong Ge, Zijun Yao, Yu Zheng. Exploiting Geographic Dependencies for Real Estate Appraisal: A Mutual Perspective of Ranking and Clustering. In the Proceeding of the 20th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2014).
[2] Yanjie Fu, Yong Ge, Yu Zheng, Zijun Yao, Yanchi Liu, Hui Xiong, Nicholas Jing Yuan. Sparse Real Estate Ranking with Online User Reviews and Offline Moving Behaviors. IEEE International Conference on Data Mining (ICDM 2014).
新闻报道:
[1] 2017.1.5:微软科学家开火锅店:用大数据选址,发现上海优于北京
——————————————————————————-
[2] 基于大数据的城市物流优化
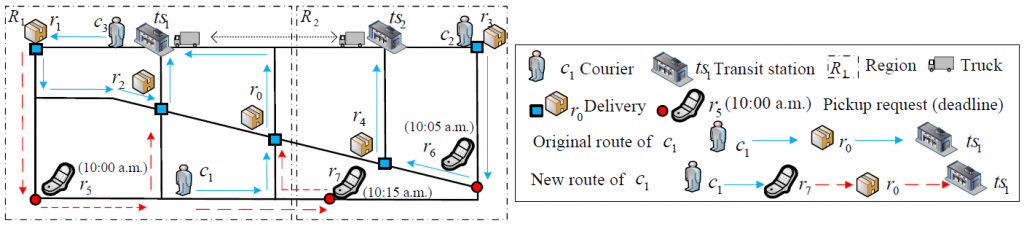
项目简介:城市中人们对收发快递的需求与日俱增,快递发送量往往超过快递员的实际运力。本项目根据快递发送者的请求位置和时间以及快递员的当前位置和后继行程,动态调度和规划快递员的快件收发路线,在不增加快递员人数的情况下大大提高整个物流系统物件的吞吐量。该项目涉及到时空数据的管理和动态查询技术,可满足大规模城市物流的需求。
论文:
[a] Siyuan Zhang, Lu Qin, Yu Zheng, and Hong Cheng. Effective and Efficient: Large-scale Dynamic City Express. IEEE Transactions on Data Engineering (TKDE)
—————————————————————————–
[3] 基于车辆轨迹的广告牌选址
项目简介:根据大规模的车辆GPS轨迹信息选取k个路口放置广告牌,使得在一段时间内这些广告牌加到一起覆盖的独立车辆数目最大,从而最大化广告效益。该项目提供提供一个交互式的高效、可视分析工具,通过跟广告选址从业者不断的交互来,将行业知识反馈给算法,从而优化最终的选址结果。这是一个把人加在数据挖掘过程中(human-in-the-loop)的一个方法。由于有交互的需求,挖掘的过程必须非常高效。
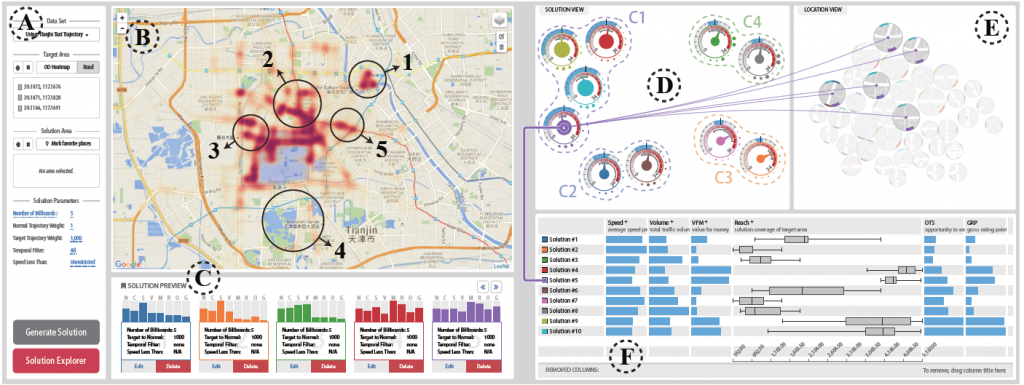
论文:
[1] Dongyu Liu, Di Weng, Yuhong Li, Jie Bao, Yu Zheng, Huaming Qu, Yingcai Wu, “SmartAdP: Visual Analytics of Large-scale Taxi Trajectories for Selecting Billboard Locations”, in The IEEE Conference on Visual Analytics Science and Technology (IEEE VAST 2016).
[2] Yuhong Li, Jie Bao, Yanhua Li, Zhiguo Gong, Yu Zheng. Mining the Most Influential k-Location Set From Massive Trajectories. IEEE Transactions on Big Data. 2017, 10.1109/TBDATA.2017.2717978.
—————————————————————————–
[4] 基于稀疏社交媒体的最佳路线轨迹
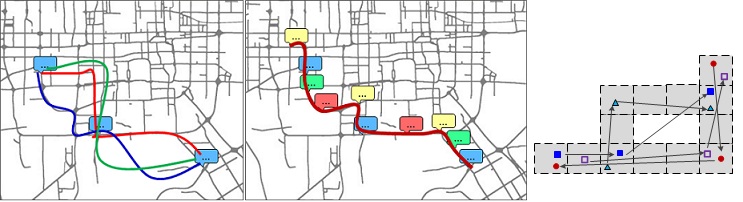
项目简介: 一个用户的签到或者带有地标的照片数据都可被看成是不确定的轨迹,因为用户不会不停的签到或拍照。给出这样一条轨迹数据时,我们无法判断出该用户选择的具体线路(如图上左1子图)。但是,当我们把很多个用户的不确定线路叠加到一起的时候,就能猜测出最有可能的线路(如上左2图所示),即“不确定+不确定=确定”。这样的应用可以帮助人们规划旅行线路。比如,一个用户想在一条线路中去后海、天坛和颐和园三个地方,他便可以把这三个点输入到系统里,我们便可根据大众的签到数据计算出一条最热门的游玩路线。
下载:
[1] Ling-Yin Wei, Yu Zheng, Wen-Chih Peng, Constructing Popular Routes from Uncertain Trajectories. 18th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2012). (Data)
[2] Hechen Liu, Ling-Yin We, Yu Zheng, Markus Schneider, Wen-Chih Peng. Route Discovery from Mining Uncertain Trajectories. Demo Paper, in IEEE International Conference on Data Mining (ICDM 2011).
—————————————————————————–
[5] 从人们的轨迹数据中发现最有趣地点和线路
项目简介:从用户大量的GPS轨迹信息中发掘城市里有趣的地点和旅行线路。该信息对旅行规划和线路推荐有着重要的价值。有趣的地点并不完全由到访的人数来决定,否则机场和火车站将会变成最有趣的地方。这些人的经验值将起到区分地点有趣程度的作用。有经验的人更加能找到高品质的餐馆和景点;反过来,有趣的地点也能吸引有经验的游客。所以,人的经验值和景点的兴趣都有一个相互依存的迭代关系。
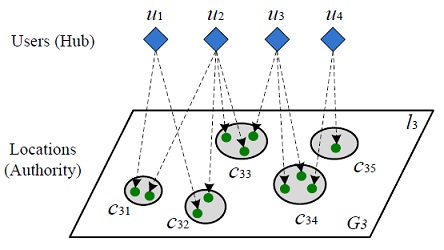
论文
- Yu Zheng, Lizhu Zhang, Xing Xie, Wei-Ying Ma. Mining interesting locations and travel sequences from GPS trajectories. In Proceedings of International conference on World Wild Web (WWW 2009), Madrid Spain. ACM Press: 791-800.
- Yu Zheng, Xing Xie. Learning travel recommendations from user-generated GPS traces. In ACM Transaction on Intelligent Systems and Technology (ACM TIST), 2(1), 2-19.
- Download: GeoLife Trajectory Dataset
AI+城市能耗
大数据与城市能源
[1] 城市汽车油耗和尾气排放实时计算
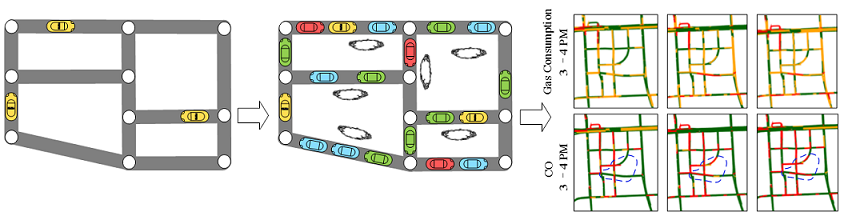
项目简介:城市交通流跟能耗和污染排放这两个重大问题都紧密相关。准确理解整个城市的汽车油耗和尾气排放情况有助于节能减排,对一个城市的持续发展和保护人们的健康至关重要。本项目先通过出租车的GPS轨迹数据计算已有数据路段上的车辆行驶速度,然后再结合兴趣点和路网结构等其它数据源,将有限的速度信息,利用协同过滤的机制传播到整个路网。然后,利用图模型将每条到路上的速度信息转化为车流量信息。最后,通过环境学理论,根据车速、流量和平均排量计算出能耗和尾气排放情况。这项研究不但可以向用户建议最低油耗路线,还可以做到细粒度的空气污染预警。对于长期数据的分析,还可以发现城市中高能耗路段(建议改进城市规划),并帮助分析汽车尾气排放的PM2.5占空气中总量的比重,从而为政府决策提供参考建议,如限制交通流量是否真的能够减缓污染情况 (参看以下第一篇文献)。
下载:
[1] Jingbo Shang*, Yu Zheng, Wenzhu Tong, Eric Chang. Inferring Gas Consumption and Pollution Emission of Vehicles throughout a City. In the Proceeding of the 20th SIGKDD conference on Knowledge Discovery and Data Mining (KDD 2014).
[2] 实验数据
[3] 联合国报道:United Stations Global Pulse
———————————————————————
[2] 城市人群加油行为分析
利用装有GPS的出租车在加油站的等待时间去估计加油站的排队长度,从而估算出此时加油站内的车辆数目及加油量。通过将全城的加油站数据汇总,便可计算出任意时刻有多少燃油被消耗掉(加入到汽车的油箱里)。这项研究成果给需要加油的用户提供推荐信息,寻找排队时间最短的加油站。其二,可让加油站运营商知道各个地区的加油需求,从而考虑增加新的站点或动态调整某些加油站的工作时间。其三、政府可以实时掌握整个城市的油耗,制定合理的能源战略(参看以下第2和3篇文献)。
论文:
[1] Fuzhen Zhang, David Wilkie, Yu Zheng, Xing Xie. Sensing the Pulse of Urban Refueling Behavior. 15th ACM International Conference on Ubiquitous Computing (UbiComp 2013)
[2] Fuzheng Zhang*, Nicholas Jing Yuan, David Wilkie, Yu Zheng, Xing Xie. Sensing the Pulse of Urban Refueling Behavior: A Perspective from Taxi Mobility. ACM Transaction on Intelligent Systems and Technology (ACM TIST). 2015.
PPT下载和在线视频讲解
- 2017年8月:城市计算在KDD 2017( 4小时)专题讲座
- 2017年4月:CCF ADL 1小时报告 [视频讲解:深度学习在深空数据上的探索]
- 2017年3月29日Tutorial at DASFFA2017:Urban Computing: Enabling Intelligent Cities with AI and Big Data (80分钟)
- 2017年3月清华1小时演讲:城市计算:用大数据和AI驱动智能城市(视屏和讲解)(PPT)
- 2017年2小时分享:多源数据融合和时空数据分析(讲解)
- 2017年45分钟城市计算keynote speech:用大数据驱动城市智能
- 2016年CNCC:AlphaGo中的人工智能技术及其在时空数据中的应用
- 2016年城市计算-规划篇(60分钟)
- 2016年城市大数据平台 (30分钟)
- 2016年城市计算在交通领域应用(60分钟)
- 2016年城市计算概述(90分钟)
- 2015年城市计算概述(150分钟)
- 2015年 城市计算-环境篇(70分钟)
- 2015年 城市计算应对空气污染(60分钟)
- 2015年数博会20分钟发言ppt
- 清华大数据课程 城市计算 6节课讲义
- 半小时报告 ppt -2014
- 1小时报告ppt -2014
数据下载
[1] T-Drive Taxi Trajectroies: 北京市10,000辆出租车1星期的GPS轨迹数据.
[2] GeoLife Trajectory Dataset: 167名用户三年多(2007.4-2010.12)的GPS轨迹数据。数据采集于 GeoLife项目。
[3] Taxi request simulator: 根据出租车乘客上下车真实记录而产生的用户打车请求发生器,可以模拟整个城市里面人们的出行需求。
[4] Check-in data from Foursquare: 来自于FourSquare的社交媒体数据。每个check-in包括时间、地点和POI类别。
[5] Air quality data of Beijing and Shanghai: 北京和上海的空气质量数据(2013-2-8 to 2014-2-8).
[6] Traffic and geographical features of each road segments: 从出租车轨迹、路网和POI数据中提取的特征,可用于交通流量计算.
[7] Noise complaint data and geographical data of NYC: 311噪音数据以及从路网、POIs.
[8] 中国43个城市的空气质量、气象和天气预报数据。可用与空气质量细粒度分析和预报。
[9] 自行车租赁系统数据:包含每一辆车的借出和还回时间和站点ID,包括对应时间的天气信息。
[10] 多源数据的异常检测:包括纽约市的311数据、出租车数据和自行车的数据,并对应的隐含POI和路网信息,共物种数据源。
[11] 城市人流数据: 包括北京市每一平方公里范围内在半小时内的流入和流出出租车数量,以及纽约市各个自形成租赁点每小时的自行车的借出和还回数量.
People

Yu Zheng
Vice President and Chief Data Scientist, JD Technology Group